
Алгоритм LSA (Latent Semantic Analysis) является одним из основных инструментов в области обработки естественного языка. Он применяется для анализа и сравнения текстовых документов с целью поиска похожих материалов. Как правило, LSA используется в информационных поисковых системах, где необходимо быстро и точно находить подходящие документы для пользователей.
Принцип работы алгоритма LSA основан на математической модели, которая представляет документы в виде векторов в многомерном пространстве. При этом каждый документ представляется не отдельными словами, а семантическим значением, которое оно несет. Таким образом, алгоритм LSA позволяет учесть скрытую семантику текста и найти схожие документы даже при отсутствии точного совпадения слов.
Алгоритм LSA состоит из нескольких основных шагов. Сначала строится матрица терм-документ, где каждый столбец соответствует отдельному документу, а каждая строка соответствует отдельному терму (слову). Затем применяется метод сингулярного разложения (Singular Value Decomposition, SVD), который позволяет разложить матрицу на три компонента: две ортогональные матрицы и диагональную матрицу. Далее происходит сокращение размерности, путем отбрасывания наименее значимых элементов диагональной матрицы. После этого можно сравнивать документы, вычислять сходство и находить наиболее похожие.
Использование алгоритма LSA для поиска похожих документов имеет ряд преимуществ. Во-первых, он позволяет находить связи и семантические соотношения между текстами даже в случаях, когда они не содержат точных совпадений по словам. Во-вторых, алгоритм LSA является достаточно эффективным и быстрым инструментом для обработки больших объемов текстовой информации. В-третьих, он может применяться для ранжирования найденных похожих документов, учитывая их сходство и важность.
Что такое алгоритм LSA и как он работает?
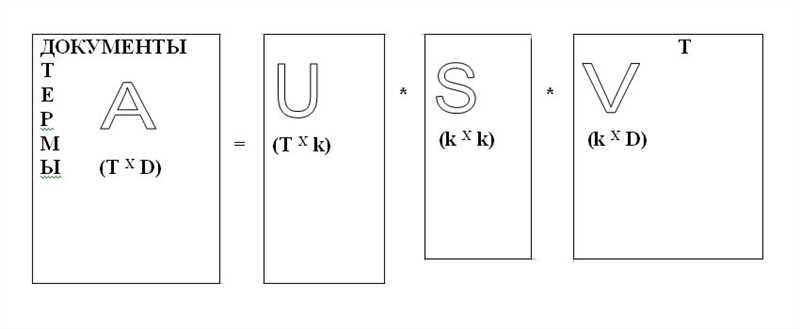
Основная идея алгоритма LSA заключается в том, чтобы представить каждый документ в коллекции в виде вектора, который будет содержать информацию о семантическом значении этого документа. Для этого применяется матричная факторизация сингулярных значений (Singular Value Decomposition, SVD), которая позволяет разложить матрицу слов и документов на уменьшенное число измерений, сохраняя при этом основные семантические характеристики документов.
В итоге получаются новые векторы, которые называются «семантическими пространственными представлениями», где каждая координата вектора соответствует семантическому «измерению». С использованием этих векторов можно производить расчеты похожести между документами. Например, сравнивая угол между векторами документов, можно определить степень их семантической близости.
Применение алгоритма LSA в информационном поиске

На первом этапе алгоритма LSA происходит построение матрицы термы-документы, где каждому терму и каждому документу соответствует определенное числовое значение. Затем с помощью сингулярного разложения матрицы происходит сокращение размерности, что позволяет учесть главные семантические особенности текстов.
Преимущества применения алгоритма LSA в информационном поиске:
- Позволяет учесть семантическое сходство текстов, даже если они содержат различные слова или фразы.
- Сокращение размерности матрицы позволяет ускорить вычисления и снизить потребление ресурсов.
- Алгоритм LSA может быть успешно применен для поиска похожих документов в различных областях, таких как научные статьи, новостные тексты, электронные книги и другие.
Применение алгоритма LSA в информационном поиске позволяет улучшить эффективность поиска и точность выдачи релевантных документов. Он позволяет учесть не только синтаксические, но и семантические особенности текстов, что повышает качество результатов поиска.
Преимущества и ограничения алгоритма LSA

- Универсальность: LSA может быть применен к любому типу текстовых документов, включая новости, научные статьи, блоги и другие. Это делает его универсальным инструментом для поиска и анализа информации в различных областях знаний.
- Снижение размерности: Одним из основных преимуществ LSA является способность снижать размерность пространства документов. Это позволяет сократить количество признаков, используемых для представления текстов, и упрощает вычисления и анализ.
- Поиск похожих документов: LSA позволяет находить схожие документы на основе семантической близости. Это означает, что он может найти документы, которые содержат сходную информацию, даже если они используют разные слова или фразы.
- Поддержка нечеткого сравнения: LSA способен обрабатывать нечеткий запрос и находить документы, которые соответствуют этому запросу в высокой степени вероятности. Это полезно, когда пользователь не может точно сформулировать запрос или не знает точный термин для поиска.
Несмотря на все преимущества, алгоритм LSA имеет и некоторые ограничения:
- Зависимость от качества предварительной обработки данных: LSA требует тщательной предварительной обработки текстовых данных, включая токенизацию, удаление стоп-слов и приведение слов к нормальной форме. Неправильная обработка данных может привести к неправильным результатам алгоритма.
- Чувствительность к выбору размерности: Выбор оптимальной размерности матрицы для сингулярного разложения (SVD) может быть сложной задачей. Неправильный выбор размерности может привести к потере важной информации или созданию шумовых данных.
- Отсутствие учета контекста: LSA не учитывает контекст, в котором берутся слова или фразы. Он рассматривает каждый документ как набор независимых слов, что может привести к некорректным результатам в некоторых случаях.
- Трудность интерпретации результатов: LSA создает абстрактную математическую модель текстов, которая может быть сложна для интерпретации человеком. Иногда результаты могут быть неочевидными или непонятными, требуя дополнительного анализа и толкования.
В целом, алгоритм LSA является мощным инструментом для поиска похожих документов, но его использование требует тщательной предварительной обработки данных и оценки результатов. При правильном использовании LSA может значительно улучшить качество поиска и анализа текстовой информации.
Наши партнеры: